


In the last section of the previous episode, I shared some doubts about the project. After two weeks of study, most of these doubts now have answers. Of course things can change quickly so it’s possible that in future updates, some of the answers below may evolve. Let’s go through them one by one.
Solved issues
To recap, my previous doubts concerned some high-level technical decisions. Last time, I focused on outlining the idea and highlighting the significance of the fake news problem.

1. What kind of model do we want to use?
Initially we were deciding between Llama 3.1 (70b) and GPT-4.o (though, as I write this, OpenAI has released a new version of their model). We opted for the former, largely because I’ve already worked with Llama, unlike GPT-4.o. The decision didn’t rest solely on that, but prior experience with Llama was definitely an advantage.
To make an informed choice I reviewed the documentation for both models and to my surprise, found that both have the same context window size—128k tokens. If you’re unfamiliar, the context window refers to how much information (measured in tokens) a language model can "remember" at one time. Exceeding this limit means the model loses track of earlier information.
There’s no direct benchmark comparison between Llama 3.1 (70b) and GPT-4.o from Meta, but I now know that OpenAI's model generally outperforms Llama. According to Meta, only Llama 3.1 (405b) is comparable to GPT-4.o.
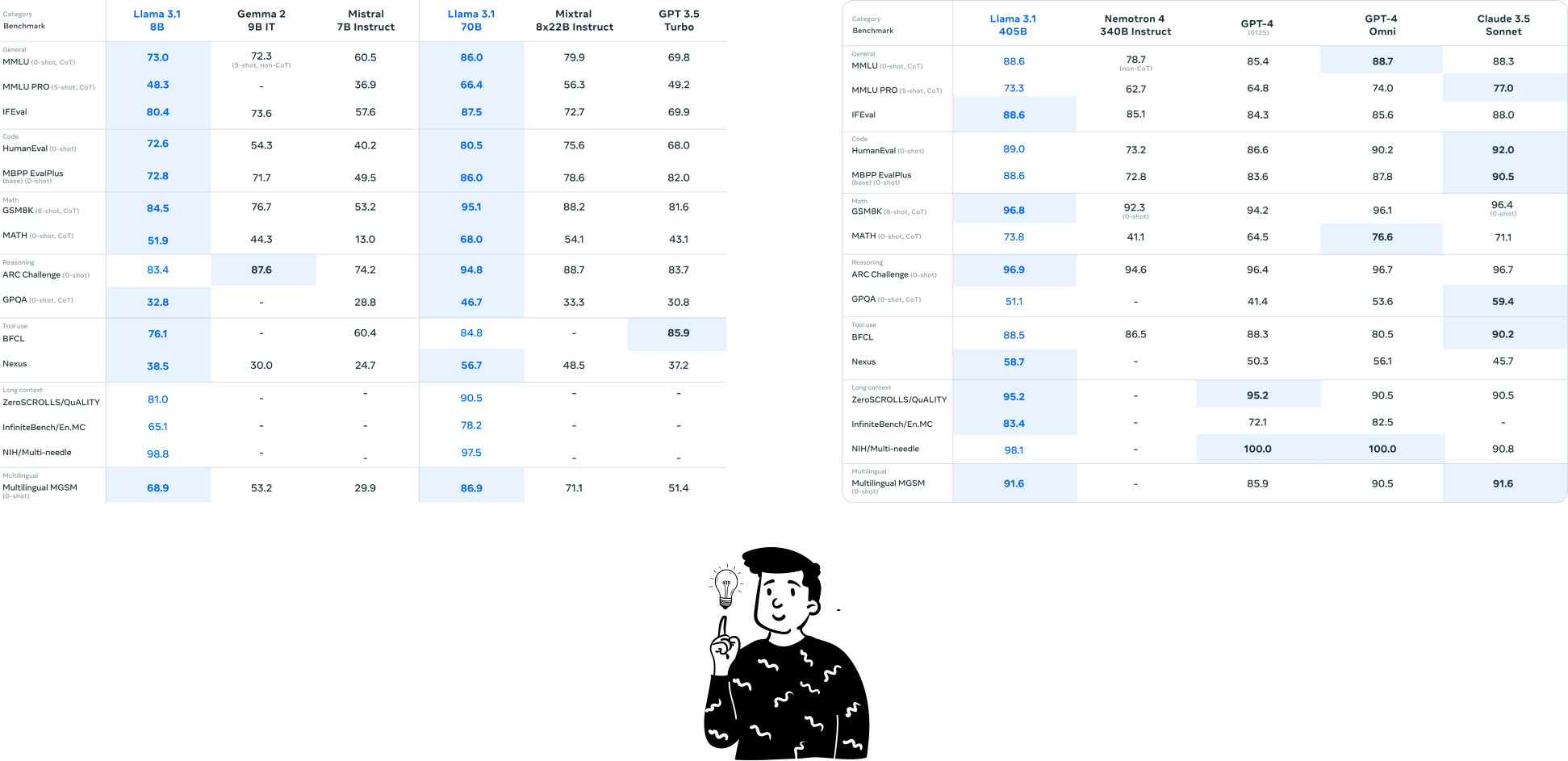
As you can see, Llama 70b outperforms GPT-4.o in two benchmarks and is fairly close in others.
Another factor we considered was cost. From our previous project (One2split), we still have credits on OVHcloud through Bocconi University, which means we can test our idea with Llama at no cost. In contrast, using GPT-4.o would incur charges for each API call, especially during fine-tuning.

In summary, here are the reasons we chose Llama 3.1 (70b) over GPT-4.o:
Both Daniel and I have experience using Llama, making it easier to work with.
Both models have the same context window.
Llama performs better than expected in benchmarks.
Thanks to OVHcloud credits, we can develop a proof of concept for free.
2. To tackle this problem should we focus more on fine-tuning or RAG?
The goal of our model is to retrieve information from trustworthy databases to verify text provided by the user (such as a tweet) against this information.
By definition this means the project is more suited for RAG (Retrieval-Augmented Generation). But just relying on the definition wasn’t enough, so I conducted further research.
While researching the first question I came across some interesting insights on fine-tuning from OpenAI’s developer page:
Fine-tuning OpenAI text generation models can make them better for specific applications, but it requires a careful investment of time and effort. We recommend first attempting to get good results with prompt engineering, prompt chaining (breaking complex tasks into multiple prompts).
In other words, OpenAI advises focusing on prompt engineering before diving into fine-tuning. Although this advice applies specifically to OpenAI models, the concept can be applied to all large language models (LLMs).
I also reviewed a paper suggested by Daniel, titled Retrieval-Augmented Generation for Large Language Models. It summarizes best practices when using RAG, and I’ll be posting a review of it in the coming weeks. For now, let’s focus on the difference between fine-tuning and RAG, and why RAG is better suited for our needs.
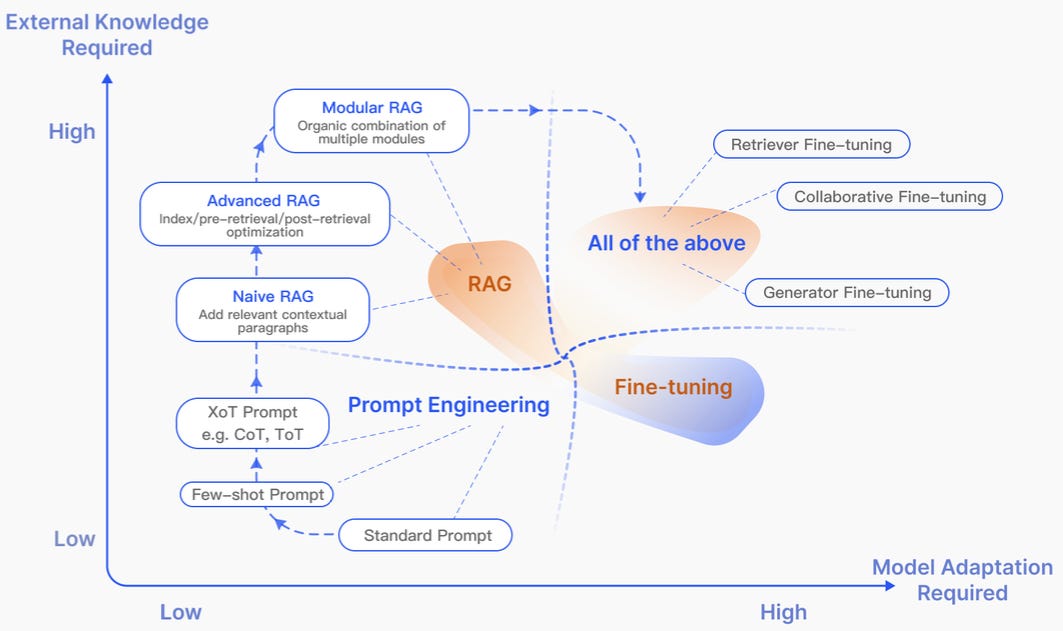
The key difference lies in how the two integrate into a model. Fine-tuning requires significant model modifications, which translates to more computational power, more energy, and well-structured datasets—something that could pose a challenge when dealing with live data streams. On the other hand, RAG is less demanding in terms of model changes and can be modular. An added advantage of RAG is that it can incorporate prompt engineering, making it more flexible.
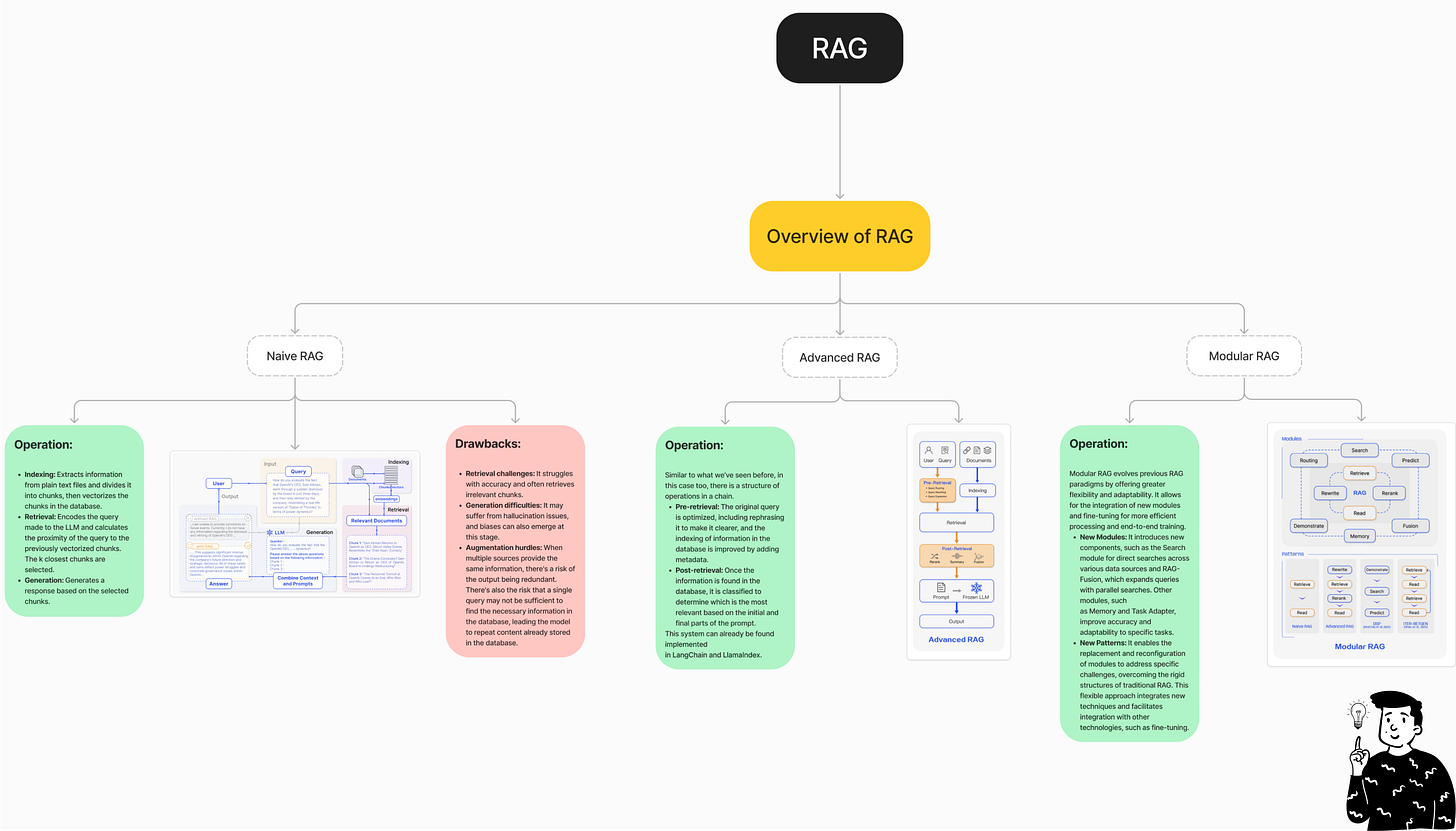
There are three types of RAG: Naive, Advanced, and Modular. I’ve created a map comparing their features. We’ve decided to use the Advanced RAG technique because we’re already familiar with it, and it’s sufficient for a proof of concept. The main difference between Naive and Advanced RAG is that the latter enhances retrieval by applying techniques like reranking, filtering, or scoring to ensure only the most relevant content is passed to the generative model.
3. If we use a RAG system where do we fetch data and keep it updated?
Keeping data updated is a challenge we’re still working on, but it’s easier than determining where to source the data from. If our model is to fact-check sentences, the quality of the data is crucial. Feeding it biased information will lead to biased outputs. Therefore, our priority is ensuring we use the most trustworthy sources before considering how easy it is to obtain the data.
Currently, I have four types of sources in mind, and I’ve created a table summarizing the pros and cons of each:
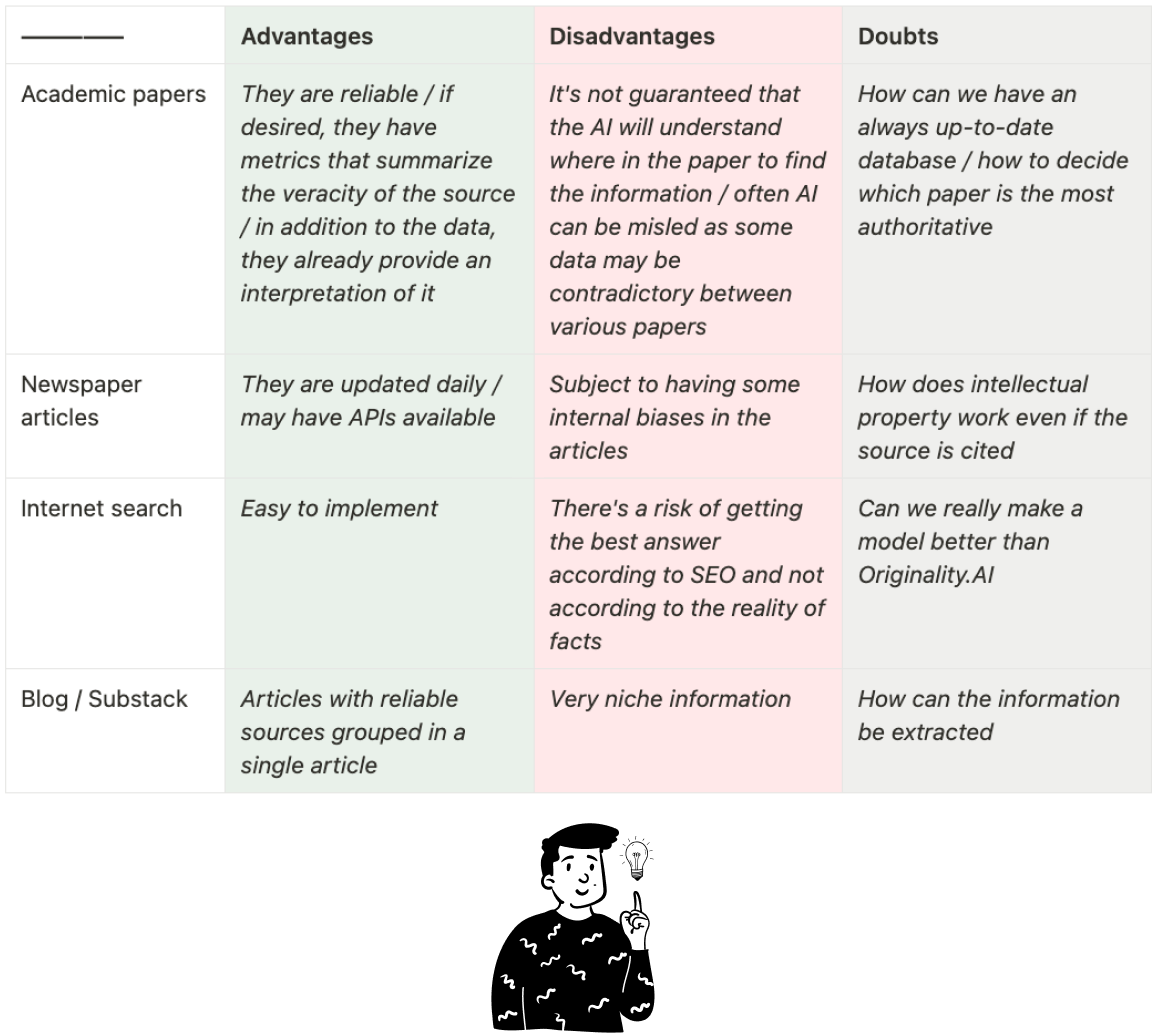
After a brief brainstorming session, Daniel and I decided to start with Italian newspaper articles for two reasons:
Their HTML structure is very static, with the entire page loading from the beginning, and the article content is clearly defined.
They publish news throughout the day, ensuring a constantly updated and reliable source.
4. How strict should the AI be?
Unfortunately, we don’t have an answer to this question yet. Once we do, I’ll share it with you.
The scraping process
To implement RAG within Llama we first need data, which we plan to retrieve by scraping websites. Specifically we want at least two sources for each news story to have cross-references, and eventually we aim to develop an algorithm that ranks news and selects the most trustworthy.
The script has been written to scrape Corriere.it, Italy’s most popular newspaper. It’s divided into sub-homepages, each dedicated to a specific topic:
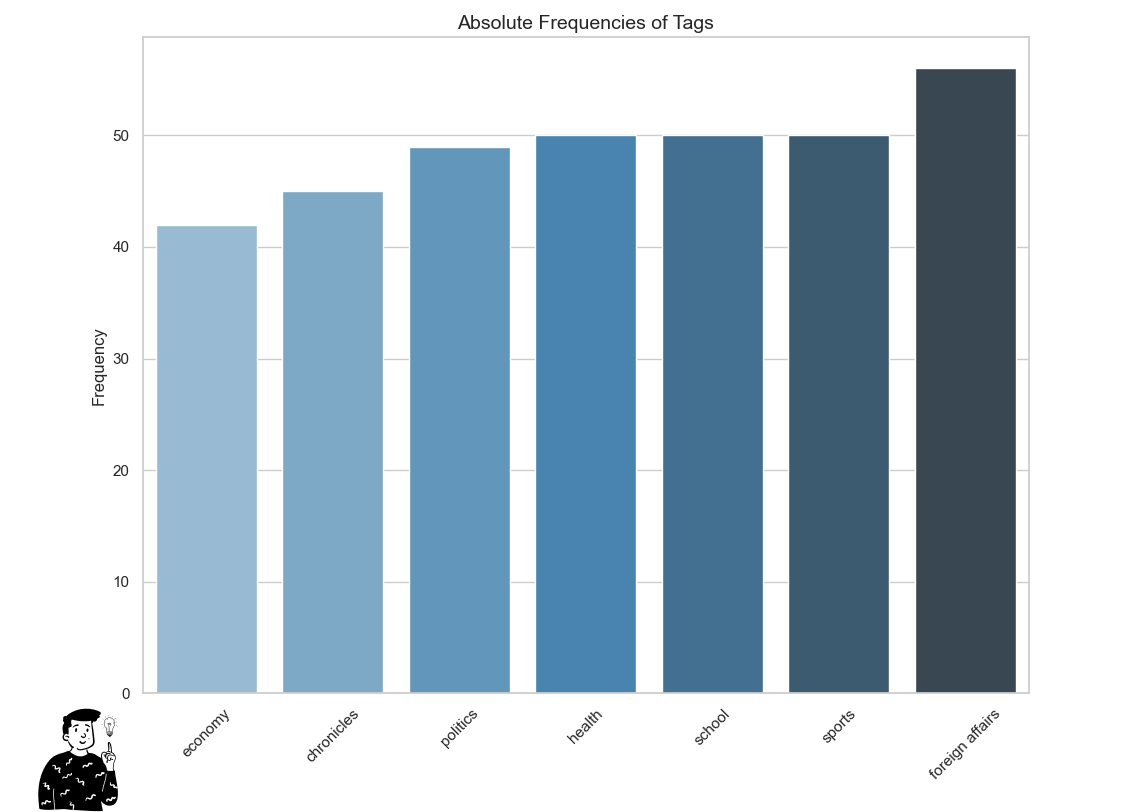
We’ve chosen seven tags: economy, news, politics, health, education, sports, and foreign affairs. The script periodically scrapes these sub-homepages, collecting news content in the form of a dictionary, which is then written into a JSON file:
dict = {
"Title" : title,
"Source" : "Corriere",
"Date" : date,
"Link" : link,
"Content" : news.strip()
}To scrape the website, I used the Readability library which is built on BeautifulSoup and provides the full HTML of a webpage with just two lines of code. The only downside is its Apache 2.0 license, meaning we’ll need to replace it if the project continues beyond testing, but for now it’s perfect.
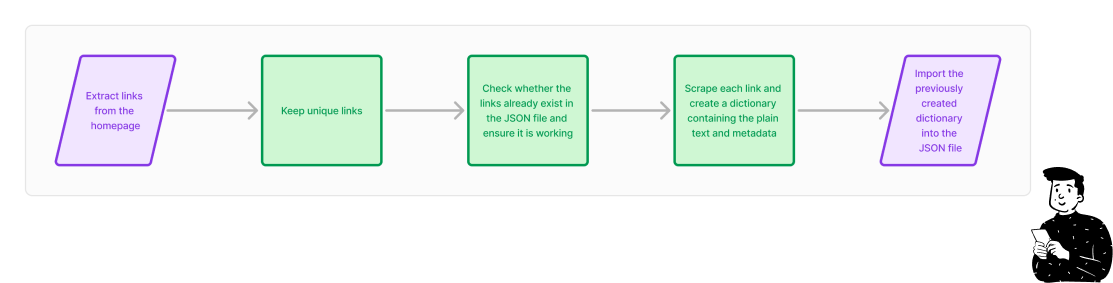
In simple terms, the script starts by scraping each sub-homepage and collecting all the links. For each link it checks two things before proceeding:
Whether the link is already in the JSON file (if so, it’s skipped).
Whether the link is alive and doesn’t return an empty page.
The first check is done with a simple if statement before scraping. For the second, the script sends a GET request and ensures the link doesn’t return a 404.

After these checks, the script scrapes the news page and retrieves the article text along with its metadata.
After running the script for an entire day, the JSON file now contains 432 news articles from Corriere.it. Here's the distribution of those articles:
This process works for most Italian newspapers, and we’re currently running it with several other sites. In the next episode, we’ll be able to upload the entire dataset into a vector database.
Next tasks
This week we also selected a virtual machine to use. Over the coming days we’ll be setting it up and installing all the necessary components. I’ll share more details in the next episode. For now, I can tell you it includes one NVIDIA L40S with 48GB of VRAM and 90GB of RAM. Simultaneously, Daniel is working on selecting the best vector database for our needs and figuring out how to evaluate the model against our two benchmark models (Llama 3.1 70b and Originality.ai).
That’s all for this episode. I hope you enjoyed the updates! If you have any suggestions, feel free to reach out to me here on Substack or LinkedIn.
(Probably if you click on my account you can already see the next episode)