


After a month since the last episode, here are some updates regarding the project to create an artificial intelligence for fact-checking. The reason I decided to wait a month before releasing a new episode is that I want to make this series a sort of logbook where the most important information about the project is encapsulated. Only once we have gathered enough new information will news be published, also out of respect for you, because I know how annoying it can be to receive too many emails.
The Work Environment
In the last episode, we ended by introducing the fact that we had found the right virtual machine for us. Since the main model for this analysis is LLAMA 3.2 70b, and we wanted to run everything locally, we were forced to choose a machine with at least 40GB of VRAM – unfortunately, we couldn't find information regarding the minimum requirements suggested by Meta.
To ensure everything runs smoothly, we chose a machine with an Nvidia L40 GPU with 48GB of VRAM and an AMD EPYC 9124 processor with 16 cores. The price is quite high for an amateur project like ours, about €1000/month + VAT, but as mentioned last time, thanks to the credit offered by OVHcloud, we’re not spending anything out of our own pocket.
For the machine setup procedure, the work was entirely done by Daniel, who, being a computer engineering graduate student, certainly has more expertise in this area than I do. What he did was create a container with Webtop in which the Fedora Linux distribution (v39) is present. If desired, we could connect directly from VS Code using the machine’s IP, but this way we have the possibility of having a very simple GUI.

Within the machine, the necessary libraries to run all the programs were installed. Mainly for the scraping part, we will use Bs4, while for the embedding procedure, RAG, and testing, we plan to use Langchain as we are somewhat familiar with the library. Of course, we will also use other libraries, which I will inform you about as we use them.
Vector DB
Another fundamental element for the project is the choice of the vector DB. We had several options to choose from, and the two that inspired us the most were:
- Pinecone
- Milvus
The first database, along with Chroma, is the most famous out there. It is certainly very reliable and well-documented (so much so that during this period I’m reading O’Reilly’s Prompt Engineering for Generative AI manual, and it uses them in the examples). However, we chose Milvus.io because it has the advantage of being very simple and doing exactly what we need at this stage, which is:
Create collections
Insert data
Search
Delete data
Embedding Process
LLama 3.2 is an encoder-decoder, which means it can translate natural language (i.e., plain text) into embeddings and vice versa. So one option could be to give the text directly to the model to get back a tensor containing all the useful information for retrieval. The other option, since it is also a decoder, is to provide a tensor as input to initiate the Augmented Generation process, thus obtaining text as output.
Our idea is to always input text, but the choice of what content to provide will be made using a model specifically created to perform similarity searches. Searching on Hugging Face, we found a new model released in September by Nvidia, NV-Embed-v2.
The reason we chose it is that, although LLama is capable of searching for similar content, this is not its main feature. Therefore, we find it more sensible to use a model specific to this task since most of the information that the AI will use will be obtained from a reprocessing of what is contained in the vector DB.
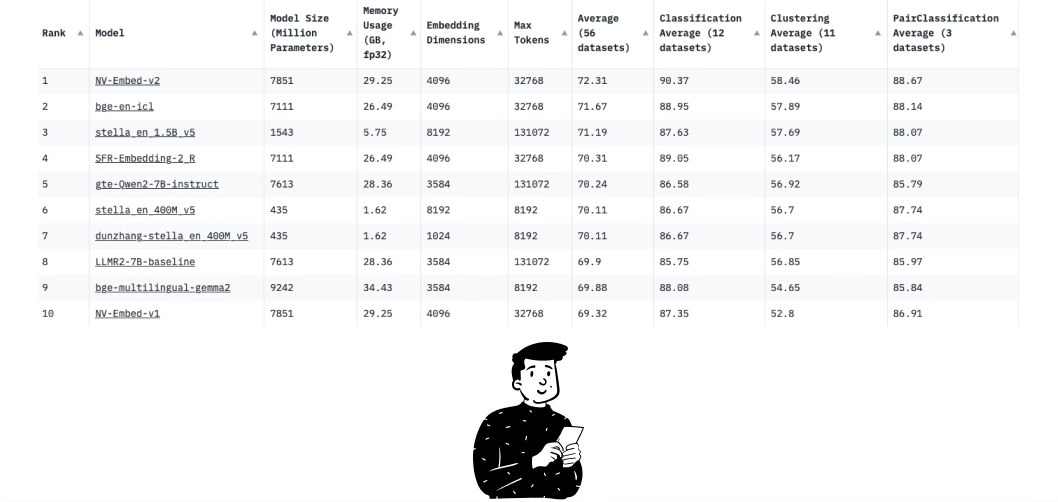
As you can see below, nv-embed-v2 is ranked first on the MTEB leaderboard on Hugging Face. It is especially powerful when performing classification, clustering, and reranking tasks – so much so that it is first in each of these categories.
In addition to looking at the model card, we took the time to read the associated paper and found that the number of tokens used in the various benchmarks was always 512. Therefore, our goal will be to divide the content of the news into chunks of the same length.
Retrieval
When wanting to use RAG, the first thing to understand, once the embeddings are done, is how to retrieve the most coherent information from the database. To do this, our idea was to use three combined methods:
The text to be verified is converted into simpler sentences with the same amount of information to be embedded by the nv-embed-v2 model, and then a similarity search is applied.
Using metadata, such as the categories the news belongs to and the source.
Implementing a sort of time decay where older news is penalized compared to newer ones.
This obviously raises several questions, such as what type of Markovian distance makes sense to use to obtain the most similar articles? How many articles should be retrieved to give to LLama? Should the categories be single words or summaries of individual chunks? Not all news can have the same time decay; some news age faster than others. How do we distinguish them? And how do we weigh them?
We do not yet have answers to these questions. Our goal is to obtain them once we start the model evaluation phase. For now, our idea is as follows:
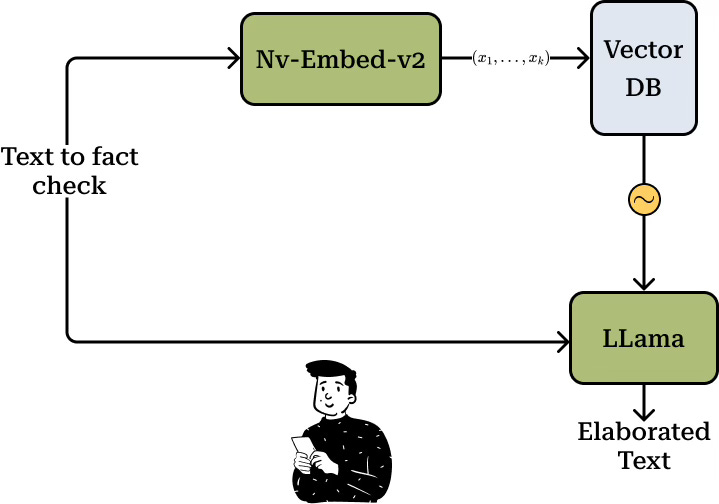
That is, articles are loaded beforehand into the vector DB using nv-embed-v2. Then, when we need to verify whether information is reliable or not, the text is passed to the same model, which performs the embedding and returns the most similar articles to the query. At this point, LLama comes into play, receiving as input the query text (we don’t yet know if a paraphrase will be performed or not) and the most similar news according to nv-embed-v2. This way, the RAG process occurs with LLama generating its output.
Chunk Creation
Before performing the retrieval of information, we need to transform it into vectors. Since we have set a limit of 512 tokens per chunk, we need to find a way to divide the body of the news into various chunks, minimizing the informational loss that will inevitably occur by splitting the content into different subsections.
To minimize this problem, there are several solutions. Upon researching, I found a Pinecone article that proposes the best solutions for dividing text into various chunks. The underlying idea is that any given text can be divided following three different logics:
By the number of basic units (which can be tokens, words, or letters)
By the number of sentences
By context
The first two methods are the most used and also the easiest to implement. The first can be easily done by running a couple of for loops and has the advantage of being extremely precise in producing chunks of equal size. However, it has the major disadvantage of being an extremely rigid process that does not adapt to the context in which it is present.
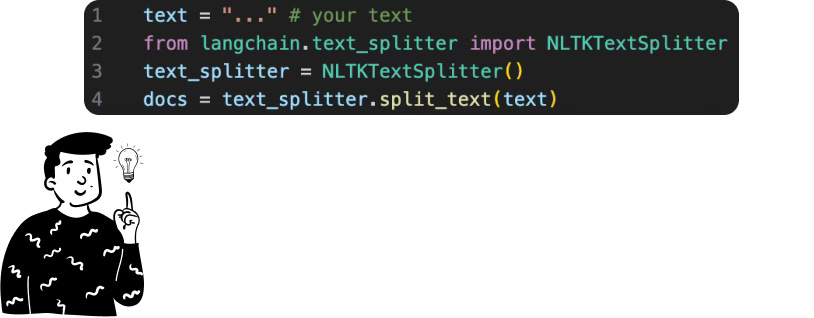
Dividing the text into chunks according to the sentences it contains is a fairly easy process to implement externally. In fact, using the NLTK library, it is possible to split the text into sentences:
For now, our idea is to divide the chunks by the number of tokens, for the reason mentioned earlier. This can, of course, be done in various ways. The methods we want to test are two:
Transform the content of the news into tokens and take exactly 512
Create an algorithm that is a hybrid approach between the first two procedures. The idea could be to divide the content into sentences (using NLTK) and then transform the sentences into tokens. For each chunk, there will be n sentences that have a total number of tokens j < 512, where the remaining 512-j tokens are some kind of padding – such as null values or a summary of the content.
Regardless of the method used, it is also necessary to consider that there will be portions of text in the various chunks that are contained in the previous chunk. On one hand, this makes the chunks more correlated with each other (and less informative), but at the same time, it helps prevent further misinterpretation of the context.
Having chosen the chunk size without considering the query size, we should ensure, in the pre-retrieval part, that the queries are adapted in a way that optimizes them for retrieval.
Problem with Embeddings
As soon as we started the embedding process, we realized that the machine was struggling significantly. In fact, for any element input, the machine was performing the process entirely on the CPU instead of using the GPU.
Interestingly, we only encountered this problem when using the PyTorch library, while using sentence.transformers did not have this issue. Upon reading the documentation, we discovered that by default, nv-embed-v2 on PyTorch prefers the CPU. Therefore, we just need to explicitly tell it to use the GPU by doing:
model.to('cuda')Once this problem was resolved, another one immediately arose, still related to the GPU. In fact, the model could only perform embeddings of 2500 characters or fewer out of 1000. Therefore, for all chunks with between 1000 and 2499 characters, the model did not have enough VRAM. To solve this problem, we looked at how the embedding function was defined within the model. By default, it is as follows:
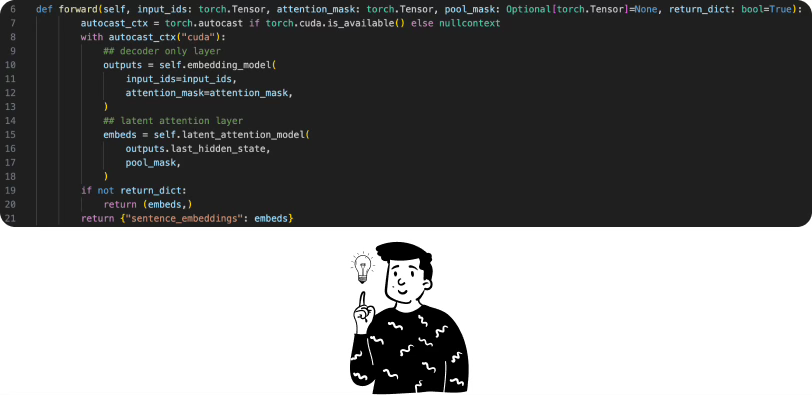
After some attempts, we noticed that the problem arose before applying the latent attention layer (i.e., after the second comment). This showed that a draft of the embedding was already available but had not yet been fully refined. The reason the GPU was overloading is related to the autocast_ctx function. In practice, this function chooses the dtype of the operations to perform. If there are more delicate operations, they are encoded with a float32, while others use float16, thereby reducing training time while minimizing information loss. On the downside, this technique requires a lot of space (definitely more than our 48GB), so we decided to disable it.
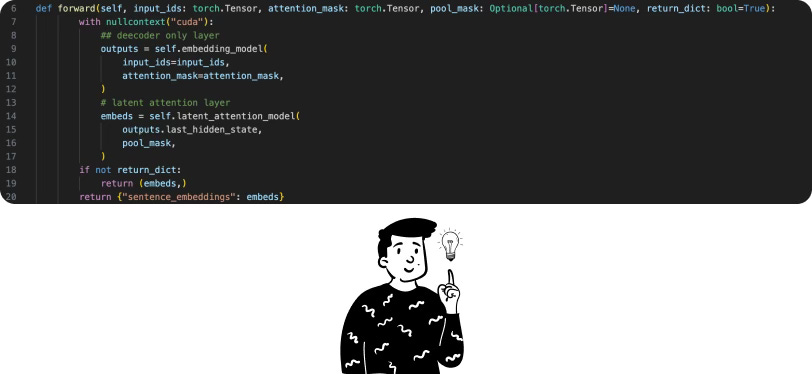
In this way, we managed to solve the GPU overload problem. In fact, during the embedding process, a maximum of 35GB of VRAM is used.
That’s all for this episode. The next steps are to start loading news into the vector DB and to see how LLama responds to the different techniques we will implement.
(Probably if you click on my account you can already see the next episode)