

Fact-checking AI, episode 1 - The foundations
In this first episode instead of just focusing on technical aspects I will cover the potential of this project and what the current state of this technology is.

The problem with the news
Disclaimer:
I’m not a sociologist or similar, so the following paragraph might be outside the scope of my expertise. What I’ve written here are some of my thoughts about the spread of fake news and why I want to build something to prevent it. If I’ve said something incorrect, feel free to correct me.
Since the beginning people have faced the problem of fake news. In fact throughout history there have been plenty of examples—one of the most notable being the theory of the Aryan race—but with globalization, we’re more exposed to them. The main reason can be attributed to the internet. According to the Pew Research Center, 58% of U.S. adults prefer getting news from digital devices (news websites, search engines, social networks, newsletters, etc.).
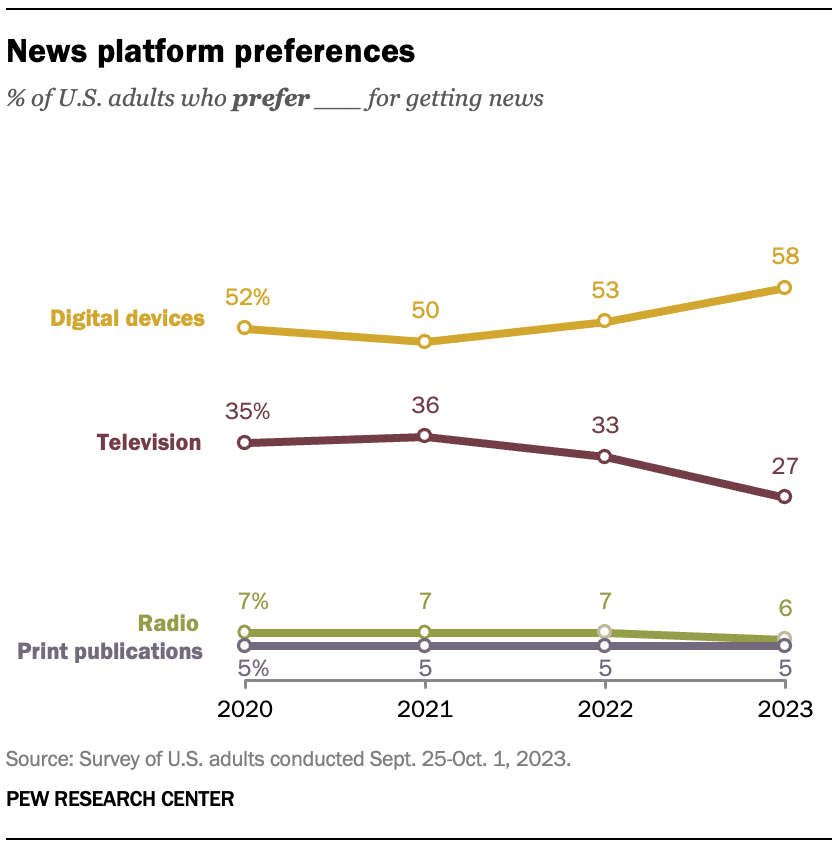
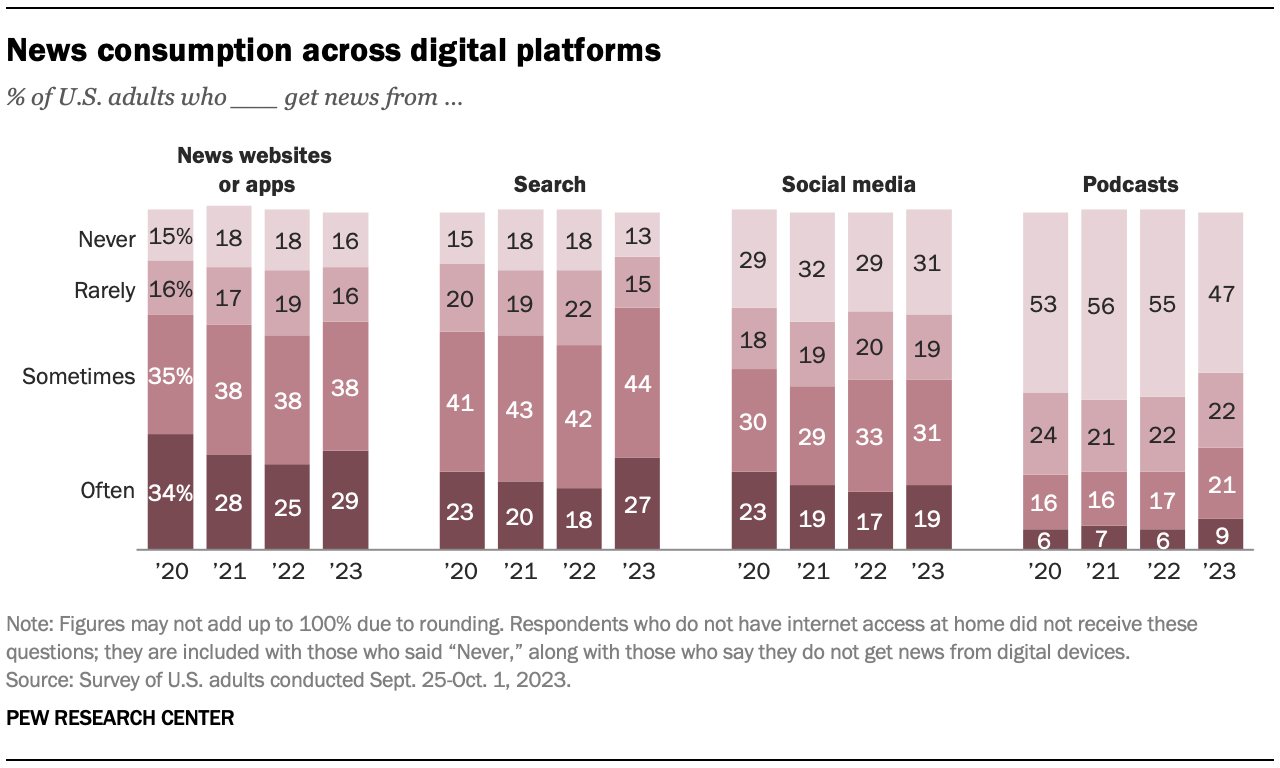
Among those people 50% use the social media sometimes or often :
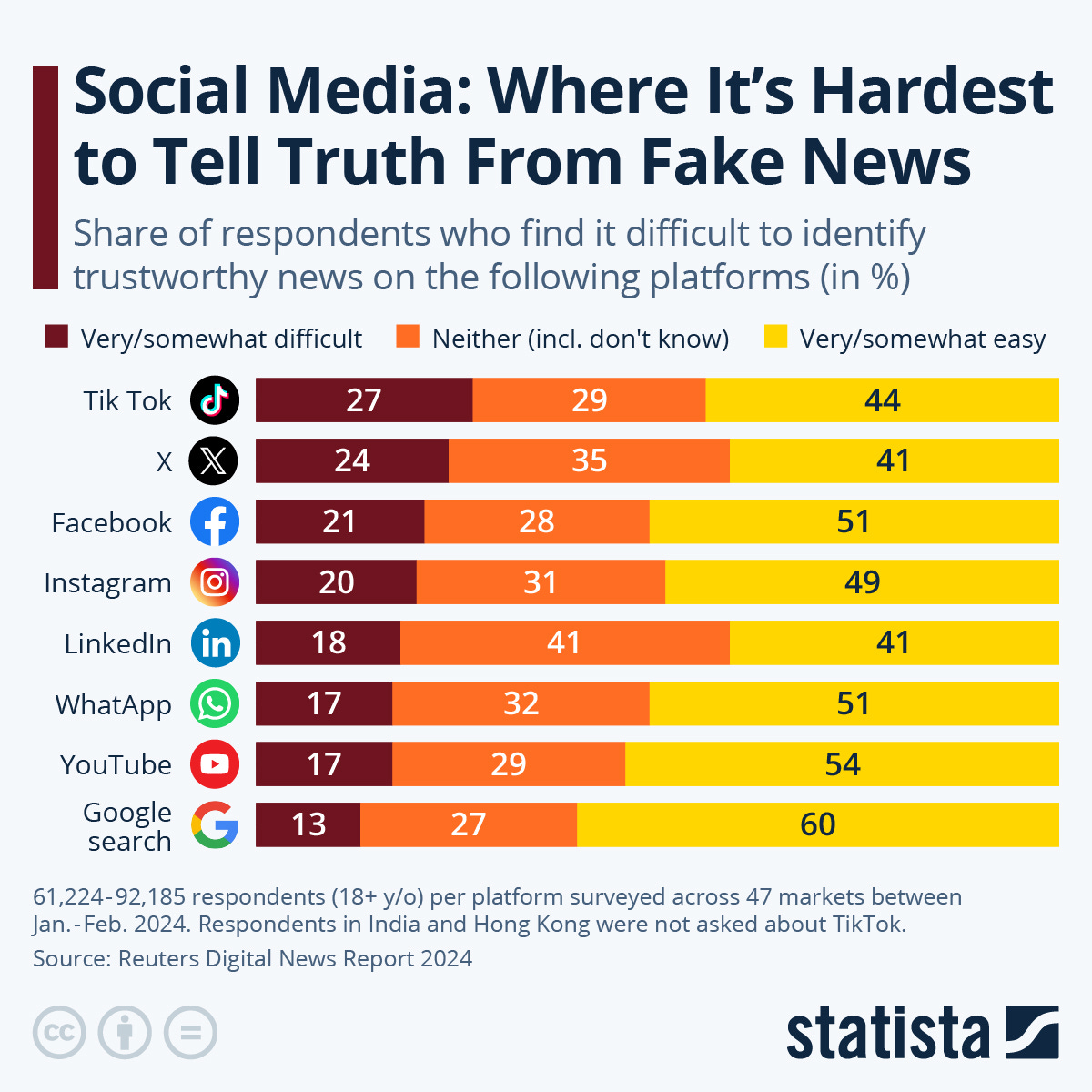
According to Statista more than one out of five news posts that people see on TikTok, X, Facebook and Instagram are difficult to identify as trustworthy:
To get an idea of the magnitude, these four social networks combined had more than 26.9 billion accesses through their websites in the last month1.
In my opinion this problem is related to the fact that fake news is more subtle today. Most people can understand whether something is completely false or not but it’s tougher for someone who isn’t an insider to know when a post presents a half-truth. For example, it’s easier to debunk someone who says that COVID has never killed anyone than someone who says that COVID has caused 94,543 deaths in Gambia. That’s because most of the time, posts and tweets don’t attach a source.
If someone presents something oddly specific, it’s more difficult to flag it as fake news because we’re often not exposed to that particular information before we read it —it’s quite difficult to know initially if COVID really killed that number of people in Gambia (spoiler: that’s just a random number).
The solution
I think it’s impossible to fact-check all the information we receive. That’s because our work and duties typically differ from fetching information and ensuring that everything we encounter during the day is trustworthy. If we tried to do this, it would be time-consuming, and we’d have to do it every time we read a new post - just imagine being on the metro scrolling your feed and every time you read a news post you have to find its source online by yourself. And if you don’t find it, what does that mean? Should the news be discarded? As you can see, in practice, retrieving the source for every news post is impossible, and often the publisher of the news (especially if it’s fake news) doesn’t provide a source. Even if a source is provided, there’s a chance it’s not trustworthy.
Luckily technology can help us, especially LLMs. The idea is to create a model that retrieves information for us and tells us if an article or post has sources that support it or not

Already existing solution
Right now some LLM uses modular RAGs in order to check if the content produced Currently, some LLMs use modular RAGs (Retrieval-Augmented Generations) to check if the content produced by their model is supported by any source. An example is Gemini by Google. In the chat window, after the model has generated its answer, a button appears that double-checks the generated content and provides a link to the source. However as I’ve seen, it has some problems with the retrieval of real-time facts and numbers. In addition it doesn’t provide papers as potential references.
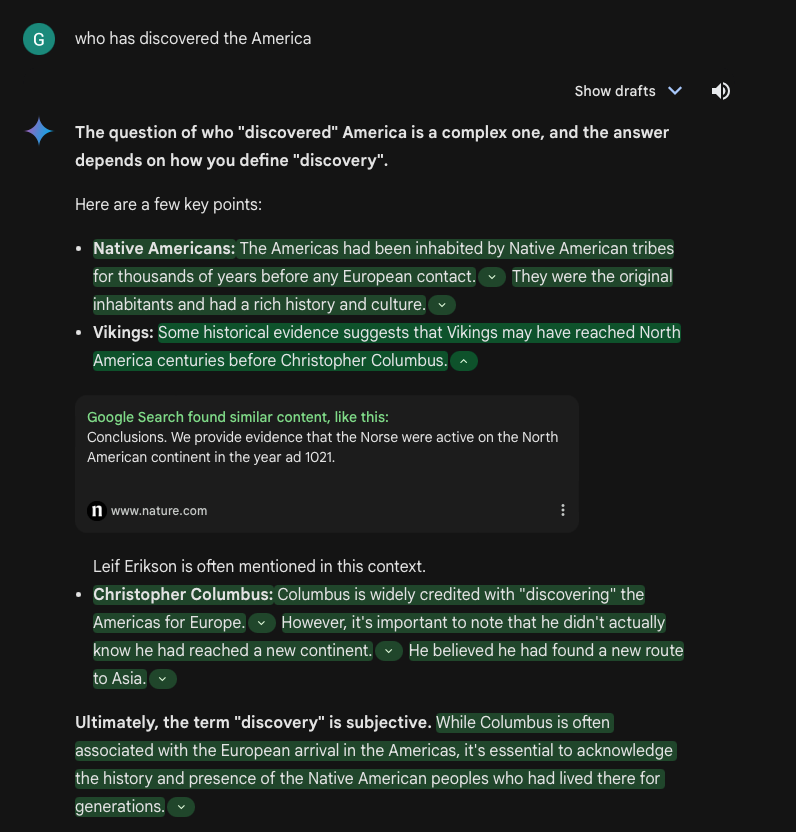
This system is also available through Bing AI, but even in this case, the fact-check is only performed on the generated content.
There is a service that performs fact-checking on the text provided Originality.ai. To use it you need credits and the retrieval of the source is restricted to a simple search on the internet and a scrape of the top three results.

On their website they claim to have a model - it isn’t specified if it’s a simple fine-tune or if they’ve built the neural network from scratch - that outperforms GPT-4 in terms of accuracy prediction. My doubt about this model isn’t just that it relies solely on the content provided by a search on the internet, which is biased by SEO optimization, but they make this claim based on testing the model with a dataset containing only 120 elements. These are the results:
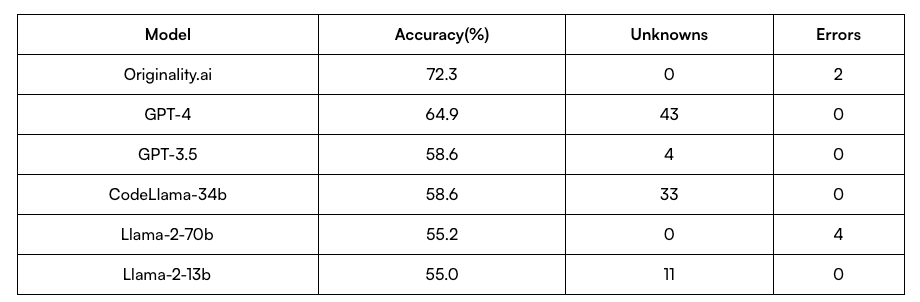
This means that 72.3% accuracy represents 87 elements correctly predicted out of 120, while 64.9% accuracy means that GPT-4 correctly predicted 78 elements out of 120. Assuming these observations are I.I.D., we can conclude that statistically, their model isn’t any different from GPT-4.
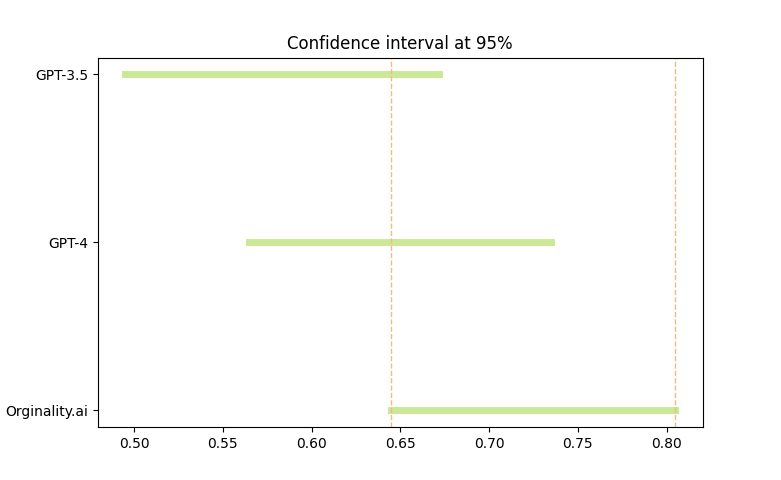
My doubts
As you can see in this article I haven’t deeply delved into the technical aspects of the project. From the next post I will focus more on them. However after a brief brainstorm with my friend these are the doubts that came up:
What kind of model do we want to use? Right now our options are two: Llama 3.1 and GPT-4, but we’re open to change, and in the coming days we’ll look forward to exploring other solutions.
To tackle this problem should we focus more on fine-tuning or RAG? Answering this will take time. Currently I’m reading a paper on it, and the most commonsense option is that both are necessary but neither alone is sufficient.
If we use a RAG system where do we fetch data and keep it updated? As we’ve seen above, performing a simple search online doesn’t provide anything more than GPT-3.5 does, so we need to find or create a database that is used alongside an online search.
How strict should the AI be? The answer to this question is probably the most uncertain of all because we have to understand what factors influence the overall accuracy score provided by the model and how to weigh errors (because mistakes are not all equal).
In the next post I will provide better answers to these questions and more technical insights.
If you have any tips or want to help feel free to message me on LinkedIn.
(Probably if you click on my account you can already see the next episode)